Disentangling Motion, Foreground and Bacground Features in Videos









Universitat Politècnica de Catalunya
Beihang University
Barcelona Supercomputing Center
[*] This work was developed during an exchange period of Xunyu Lin at the Universitat Politecnica de Catalunya.
publication
This paper instroduces an unsupervised framework to extract semantically rich features for video representation. Inspired by how the human visual system groups objects based on motion cues, we propose a deep convolutional neural network that disentangles motion, foreground and background information. The proposed architecture consists of a 3D convolutional feature encoder for blocks of 16 frames, which is trained for reconstruction tasks over the first and last frames of the sequence. The model is trained with a fraction of videos from the UCF-101 dataset taking as ground truth the bounding boxes around the activity regions. Qualitative results indicate that the network can successfully update the foreground appearance based on pure-motion features. The benefits of these learned features are shown in a discriminative classification task when compared with a random initialization of the network weights, providing a gain of accuracy above the 10%.
Find our paper on arXiv or download the PDF file. An extended abstract of this publication was accepted as poster in the CVPR 2017 Workshop on Brave new ideas for motion representations in videos II.
If you find this work useful, please consider citing:
@InProceedings{lin2017disentangling,
title={Disentangling Motion, Foreground and Background Features in Videos},
author={Lin, Xunyu and Campos, Victor and Giro-i-Nieto, Xavier and Torres, Jordi and Ferrer, Cristian Canton},
booktitle = {CVPR 2017 Workshop: Brave new ideas for motion representations in videos II},
month = {July},
year={2017}
}
Lin, Xunyu, Victor Campos, Xavier Giro-i-Nieto, Jordi Torres, and Cristian Canton Ferrer. “Disentangling Motion, Foreground and Background Features in Videos.” CVPR 2017 Workshop: Brave new ideas for motion representations in videos II (2017).
Model
We adopt an autoencoder-styled architecture to learn features in an unsupervised manner. The encoder maps input clips to feature tensors by applying a series of 3D convolutions and max-pooling operations. Unlike traditional autoencoder architectures, the bottleneck features are partitioned into three splits which are then used as input for three different reconstruction tasks. The foreground or background features are disentangled by reconstructing corresponding appearances in one frame. And the motion features are modelled as the updating of one foreground appearance to another.
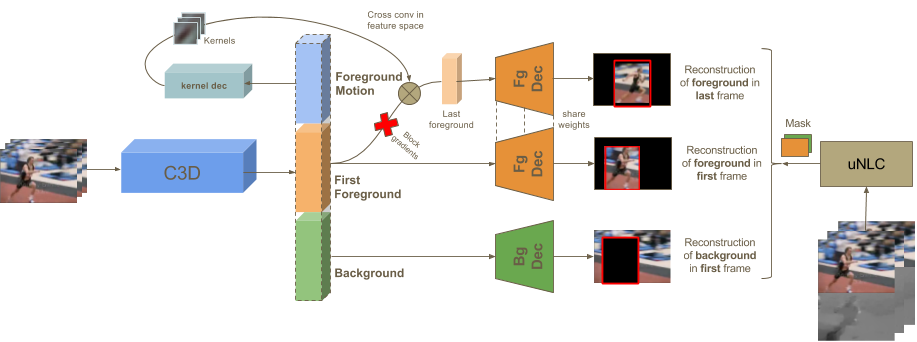
Segmentation masks used for generating ground truth here are obtained from manual labeling. However, it is worth noting that they can be obtained without supervision as well, which remains as our future work.
Examples
Reconstruction examples on the test set. For each example, the top row shows the reconstruction while the bottom one contains the ground truth. Each column shows the segmentation of foreground in first frame, background in first frame and foreground in last frame, respectively.

Results
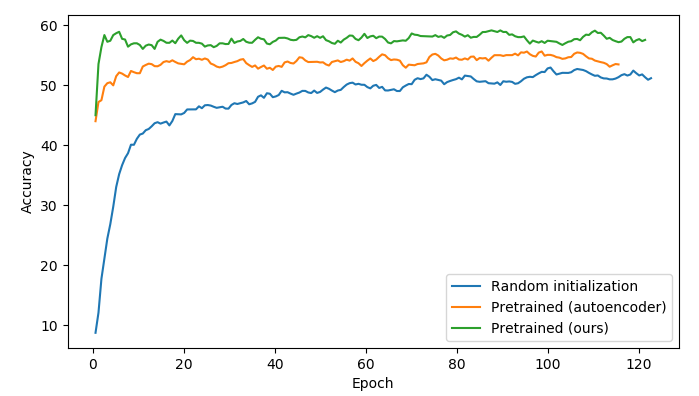
The benefits of our proposal are shown in a discriminative classification task, action recognition, where initializing the network with the proposed pretraining method outperforms both random initialization and autoencoder pretraining. The accuracy curves on validation set of all methods are shown in the figure below.
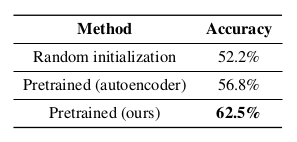
The final testing results are depicted in the table below.
code

acknowledgements
We want to thank our technical support team: